I’ve written before on why grid-search is not enough (exibit A, exibit B). In this document, I’d like to run an experiment to demonstrate the strongest reason why I believe this is true.
We need to talk about, and learn to listen to, feedback.
Applications over Models
Let’s consider a recruitment application. We’ll pretend that it is for a typical job and that we are a recruitment agency that has experience in hiring for this position. This means that we have a dataset of characteristics of people who applied that includes an indicator if they ended up being a good fit for the job. The use-case is clear: we will make a classifier that will attempt to predict job performance based on the characteristics of the applicants.

Figure 1: It starts out simple.
At this point, I could get a dataset, make a scikit-learn pipeline, and let the grids search. But instead, I would like to think one step further in the application layer. After all, we’re not going to be training this model once but many times. Over the lifetime of this application, we’ll gather new data, and we will retrain accordingly.
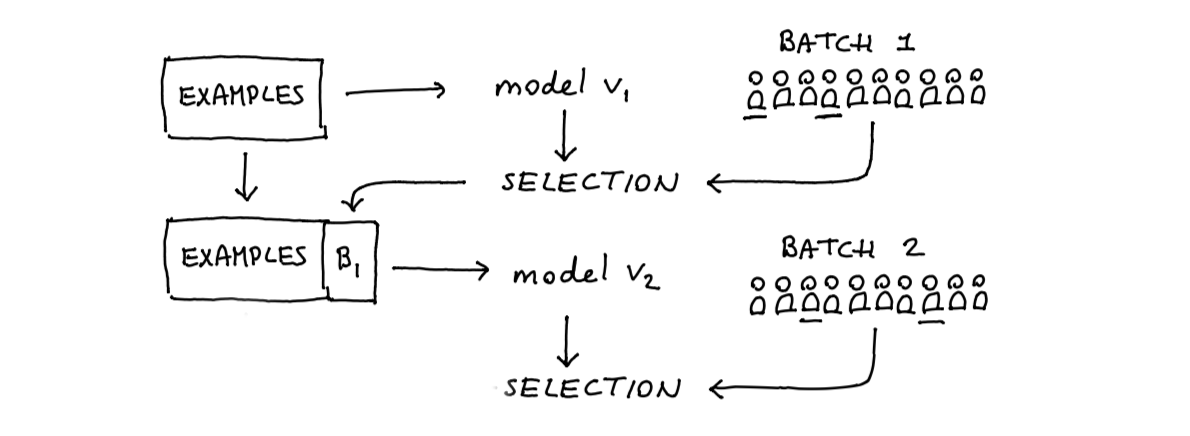
Figure 2: But the model will retrain.
First, the model is trained on the original dataset. Next, we will receive a new batch of (let’s say \(c\)) candidates. From this set, we will select the top (let’s say \(n\)) candidates who will be selected. It is from these selected candidates that we’ll get an actual label, and this will give us new data. This new data can be used to retrain the model again, such that the next round of candidates is predicted with even more accuracy.
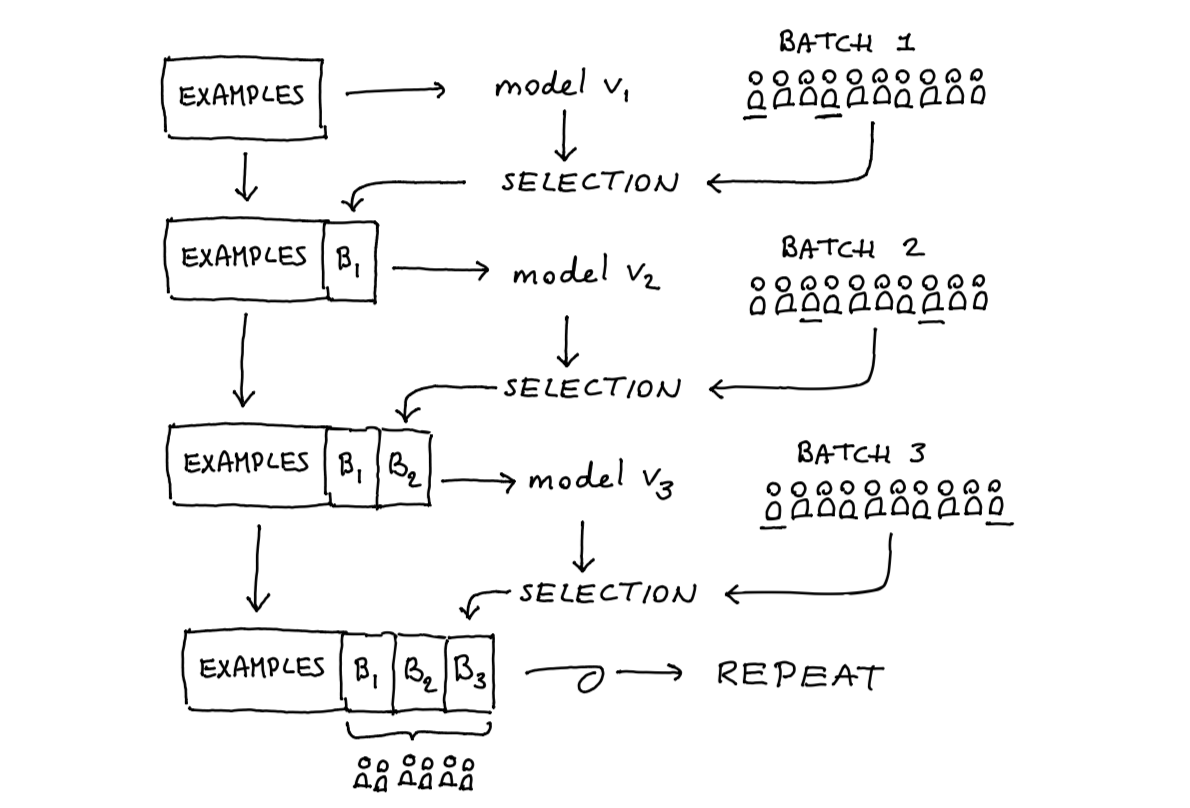
Figure 3: This model will update indefinately.
This cycle is going to repeat itself over and over.
Concerns
The crux of all of this is that we can only see the actual label from the candidates who we give a job. The rest does not get the job, and we can never learn if they would have been good for the job.
Let’s just list a few concerns here:
- if the starting dataset is biased then the predictions will be biased
- if the predictions are biased then the candidates who will be selected will be biased
- these selected candidates are the only ones who feed new data back into the mechanism
- this keeps the dataset where the algorithm can learn from biased
You might observe how the feedback mechanism is not, and cannot, be captured by the standard grid-search. Cross-validation does not protect against biased data.
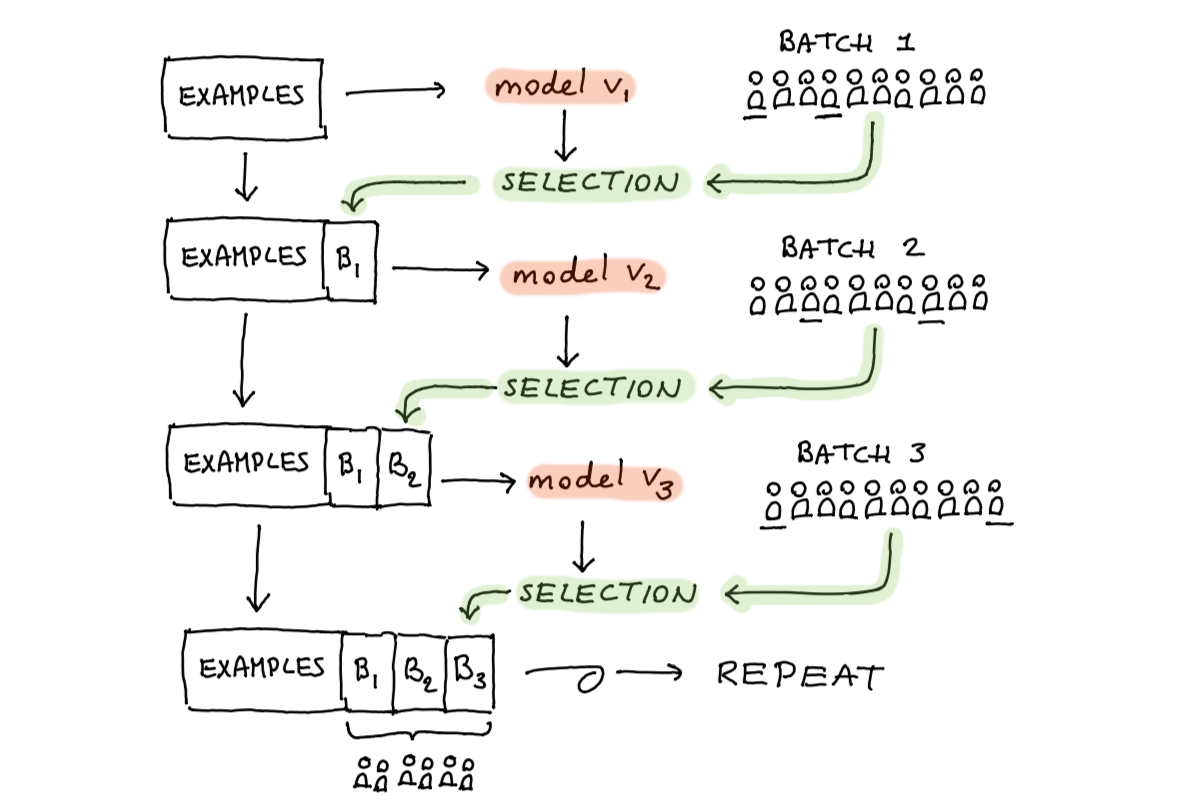
Figure 4: Which part of this system deserves more attention?
It might make sense to not focus on how we select a model (the red bits) but rather on how we collect data for it (the green bits). So I’ve set up an experiment to explore this.
Experiment
I’ve written up some code that simulates the system that’s described above. We start with a biased dataset and train a k-nearest-neighbor classifier for it. One trained, the model receives a set of 10 random candidates from the data we have not seen yet. Next, we select whichever candidates the algorithm deems the best performing. These will be the candidates that actually get a job offer, and these candidates will be able to give a label to us. The actual label of these candidates is logged, and the model is retrained. This is repeated over and over until we’ve exhausted the dataset.
We can then calculate lots of metrics. In general there are two datasets of interest. The first dataset contains all the candidates for which the system receives a label.
Figure 5: These points have been seen by the algorithm
The second dataset contains all the candidates. For a subset of these candidates we receive a label so there is overlap with the previous dataset.
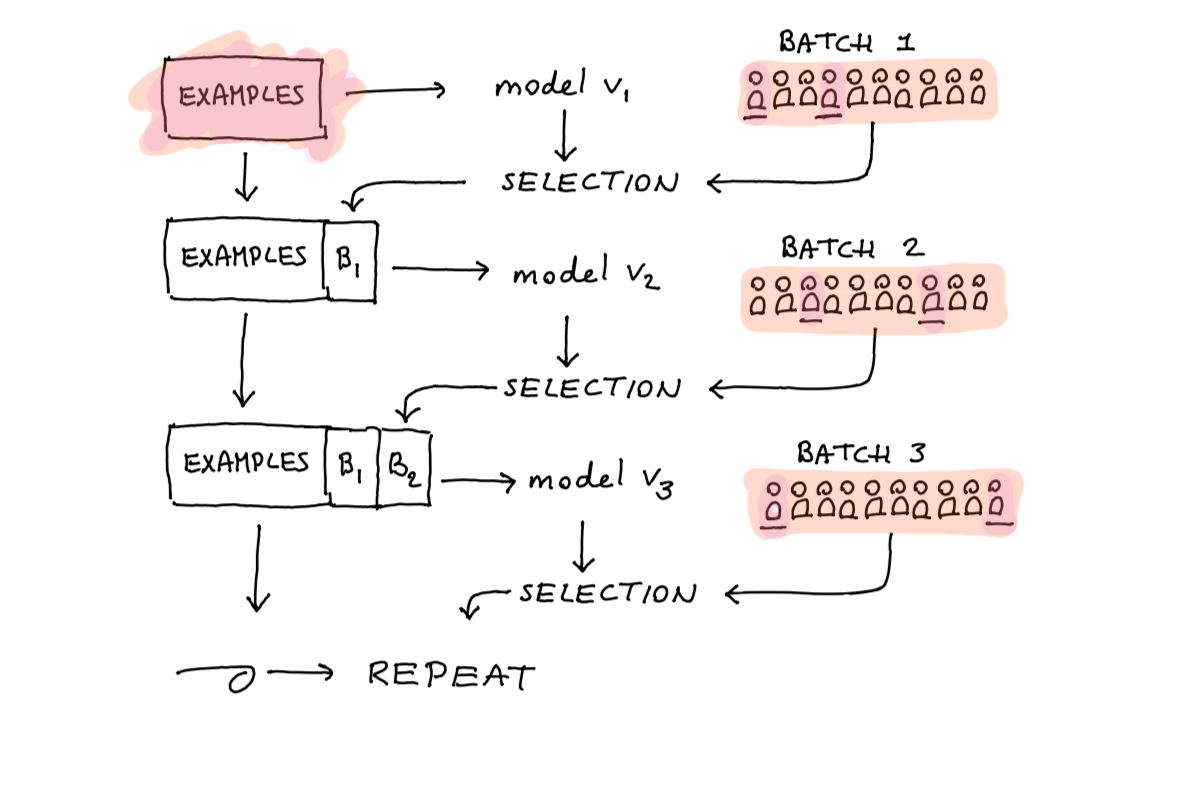
Figure 6: These points judged by the algorithm
The goal of the experiment will be to see what the difference in performance is between these two datasets.
Obvious Dataset
I’ll start with a dataset that has two clusters of candidates that have a positive label. In the plots below, you’ll see the entire (true) dataset, the subset that is taken as a biased start, the probability assignment by the algorithm and the greedily selected candidates from the models’ prediction.
I’ve also listed the scores from two sources. One set is from all the data that our system actually observes. This set contains the biased dataset we started with and the labels of the selected candidates. The other set is from all the data, including the candidates that we have not seen.
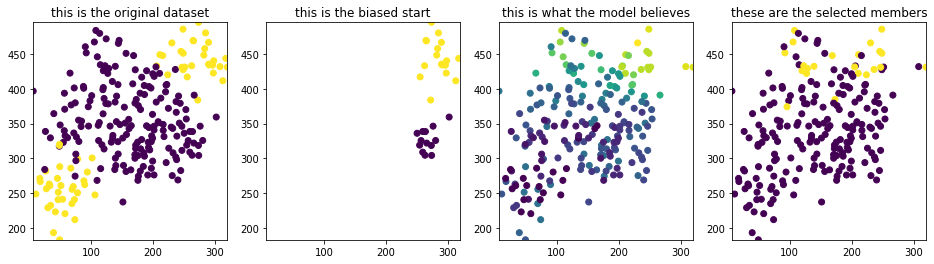
Figure 7: Plots for the easy dataset when selection 1/10 candidates
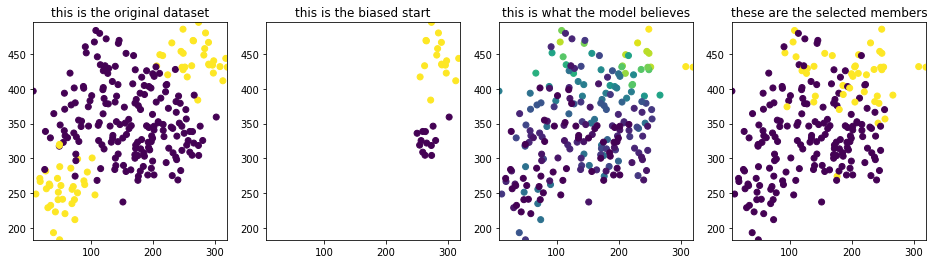
Figure 8: Plots for the easy dataset when selection 2/10 candidates
Discussion
Notice the striking difference between the entire dataset and the observed dataset! This example is a tad bit silly, though, because the dataset has two disconnected sets of groups. The odds of learning through this much bias is very slim. Will the same effect be observed when this isn’t the case? The next dataset will have a dataset where there’s one blob but still with a biased start.
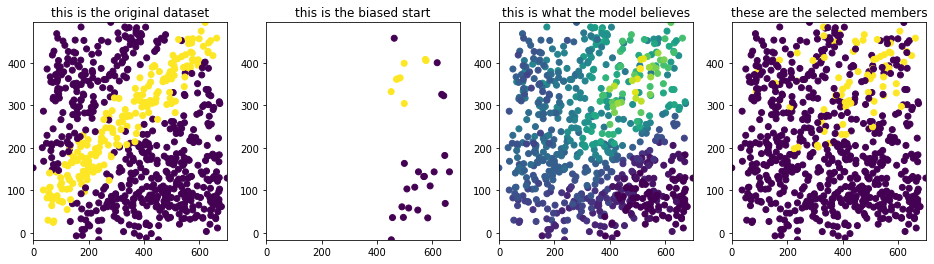
Figure 9: Plots for the easy dataset when selection 1/10 candidates
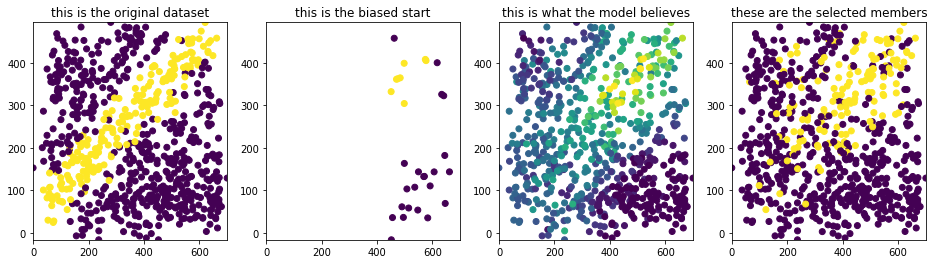
Figure 10: Plots for the easy dataset when selection 2/10 candidates
Discussion
To be perfectly honest, the comparison I am making here is not 100% fair. The model is being scored on something different than what it is being applied to.
But maybe … this is exactly the point? In this example we run a grid-search and get an overly optimistic impression of how the model would perform in production. The gridsearch cannot guarantee robustness here because both the starting dataset and the feedback mechanism are biased. It also demonstrates how the algorithm might have great difficulty escaping a self fulfilling prophecy. The gridsearch is stuck in a local optima, giving back metrics suggesting to us it is doing very well.
It doesn’t really make much sense to use a gridsearch to squeeze another 1% performance out of the algorithm if this is well within the margin of application error. The feedback mechanism is an effect that is never captured by offline data. Therefore we cannot assume cross-validation to be a sufficient insurance policy against its bias. This is a no small issue. Just think of all the use-cases that are affected by this; recruitment, fraud, law enforcement, and just about everything in recommender-land.
It might be that the relationship between your offline data and your real-life phenomenon is a reliable one. I fear however that many usecases merely have a proxy that cannot be assumed to translate perfectly to your problem. It may still deserves to be looked at but, as the Dutch might say, “you can stare yourself blind at it”.
Translation
When you apply grid search, you typically hope to squeeze another 1% of performance out of it. This makes sense but only if the problem is translated in such a way that the margin of translation error is smaller than 1%.
Let’s think about it from a birds eye view, what do people in the data science industry really do?
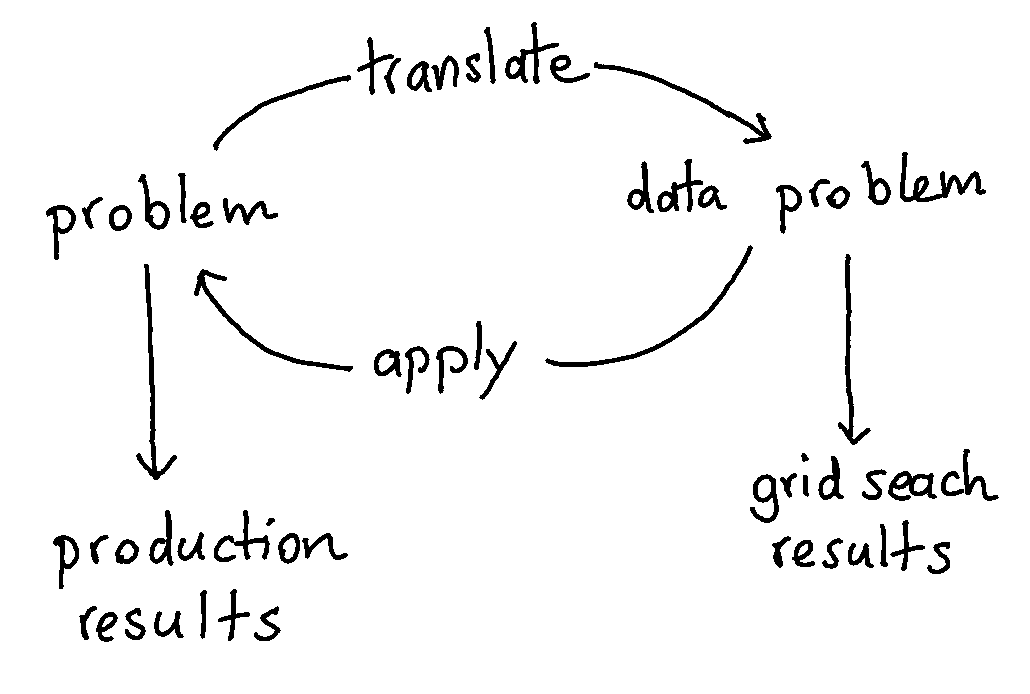
Figure 11: From PROBLEM to DATA PROBLEM back to PROBLEM
Typically one starts with a problem in real life this is translated to a data problem. This way an algorithm can handle it and we might be able to automate something. Note that there’s a risk that some aspects of the problem are lost in translation there. The question then is; will the grid-search be able to compensate for this or is the grid-search maybe making the problem worse? You need to be careful here, if the translation doesn’t 100% match the real life problem … then improvement from the grid-search might very well be insignificant compared to the margin of error introducted by the translation.
It might be good to seriously wonder if we really want to spend so many resources performing the grid analysis? Unless the test sets in the gridsearch are perfectly representative of real life then the gridsearch will always give an optimistic view. Maybe … it’s more effective to focus on the translation part of the problem instead.
Adapting the Feedback?
So what can we do with this knowledge? I have ideas but no solutions.
- When you design an algorithm, think hard about metrics and monitoring. What are all the things that can go wrong besides train/test validation and how can we keep an eye on that?
- The experiments demonstrate that the amount of candidates we select has an influence on the actual performance. Especially when you are able to select more than one candidate, then you could consider spreading a bit. One candidate might be chosen with greed in mind while the other candidate is chosen with exploration in mind. The downside remains that it can take a long time before enough candidates have been explored to end up with a less biased machine learning algorithm.
- My theory is that a lot of bias might be remedied by applying models that try to correct for fairness. This won’t be perfect but my life experience suggests that it is certainly worth a try.
- We need to ensure that all possible sources of self-fulfilling prophecies are no longer in the data we receive as feedback. When users click a product more because it is recommended, then we cannot allow this to reinforce the recommender.
- We could focus more on explainable models. This way, you’re no longer pushing a black box to production but rather an AB test that you understand. In reviewing results, this allows you to think more qualitatively about the results. This will help you understand the problem better which in turn will allow you to think more critically about potential translation issues.
- We could consider that this problem is a bit like a bandit problem. Our models will be able to exploit a reward, but sometimes we might need to add some entropy to make sure that our system continues to explore. Entropy might be a good sanity check.
- We should measure the difference between what we saw in our training phase and what we see in production. This difference is sometimes referred to as drift.
- Even in situations when we don’t always get \(y\), we do usually get \(X\). This suggest that we might be able to do some unsupervised tricks to quantify how many regions exist where we do not see any labels.
- When a user is subject to a decision that has been automated, they should have the right to know how said decision was made. This is a great boon too. This will allow them to give feedback to the systems designer. While quantitative feedback from the data can’t be trusted, the qualitative feedback from an end-user can offer clear scenarios for improvement.
All of these suggestions will depend a lot on the use-case. Common sense is still your best friend.
Focus
Most data science courses and books out there discuss the importance of doing (stochastic) grid search via cross-validation. This is undoubtedly a practice that has merit to it. Overfitting on a training dataset is a risk. Fair.
But if you’re going to apply the algorithm in the real world, then there are so many other concerns that you need to think about. Overfitting on a train set is a mere one concern. One! Putting the focus on doing just the grid-search is counterproductive because it gives a false sense of being “done” with the design of the algorithm while you’re just getting started.
It’s a general issue too. I’ve never really seen a dataset that isn’t biased in some way. My experiment here was even optimistic: I am assuming here the world does not change while a model is applied. In real life there’s also drift. Your training data will get stale and will reflect the new world less and less.
Conclusion
Grid search is a good habbit but it is simply not enough. Please be aware that you may reduce the risk of overfitting on a training set, but you are not immune to everything else that might go wrong. Things like fairness, drift, artificial stupidity and feedback mechanisms deserve more attention then they are getting now.
Code and Stuffs
You can find the notebook, python file, dataset1, dataset2 on this github gist.