R may just have become more preferable for simple webscraping jobs with the release of rvest. Before, this was something I'd prefer to do in python but the new R syntax seems to prevail. In this document I will give a small example of it's syntax.
Dependencies
library(rvest)
library(stringr)
library(dplyr)
library(ggplot2)
library(GGally)
Heroes of the storm
We will be scraping information on video game characters from heroes of the storm, a popular brawler game made by Blizzard. We'll be scraping a fan website to get the information we want.
We retrieve the website simply via the html method.
heroes <- html("http://www.heroesnexus.com/heroes")
This page contains many html nodes which have classes. These are very useful for scraping and can be accessed via a css-selector string in html_nodes. The text of these nodes can then be accessed via html_text. If you need a reminder of useful selectors, this source might help.
df <- data.frame(
name = heroes %>% html_nodes("a.hero-champion") %>% html_text,
hp_txt = heroes %>% html_nodes(".visual-quickinfo-cell .hero-hp") %>% html_text,
attack_txt = heroes %>% html_nodes(".visual-quickinfo-cell .hero-atk") %>% html_text,
role = heroes %>% html_nodes(".role") %>% html_text,
attack_type = heroes %>% html_nodes(".hero-type :not(.role)") %>% html_text
)
The nodes that we've retreived now only need to be extracted for numerical value. Through mutate we perform some etl together with some functions from stringr. If \\d* confuses you: don't worry. It's a thing called a regex: go here if you want to know more.
df <- df %>%
mutate(hp = hp_txt %>% str_extract("(HP: \\d*)") %>%
str_replace("HP: ", "") %>% as.numeric,
attack = attack_txt %>% str_extract("(Damage: \\d.\\d*)") %>%
str_replace("Damage: ", "") %>% as.numeric,
attack_spd = attack_txt %>% str_extract("(Speed: \\d\\.?\\d*)") %>%
str_replace("Speed: ", "") %>% as.numeric)
Now that the dataframe is done, let's go for some massive visual exploring with GGally.
df %>%
select(hp, attack, attack_spd, attack_type) %>%
ggpairs(data=., color = "attack_type", title="stats by melee/ranged")
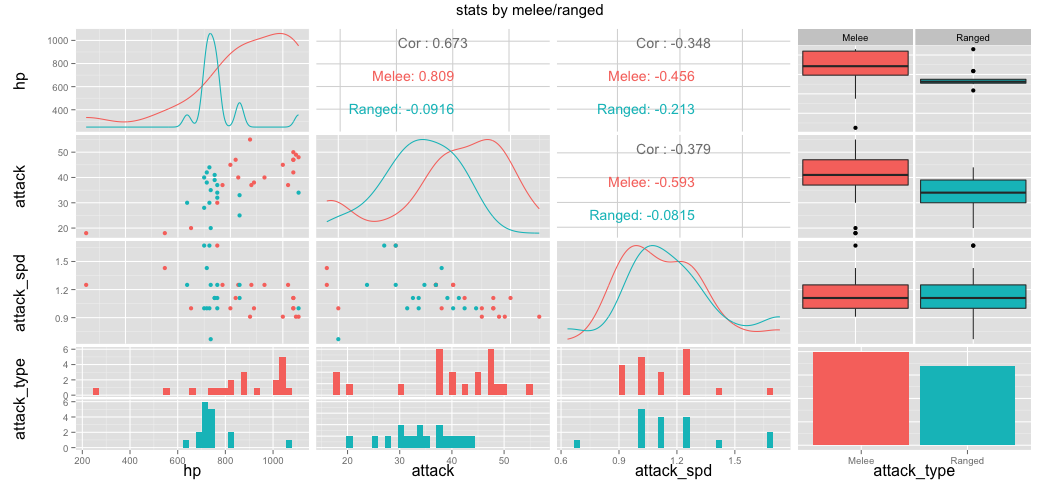
df %>%
select(hp, attack, attack_spd, role) %>%
ggpairs(data=., color = "role", title="stats by role")
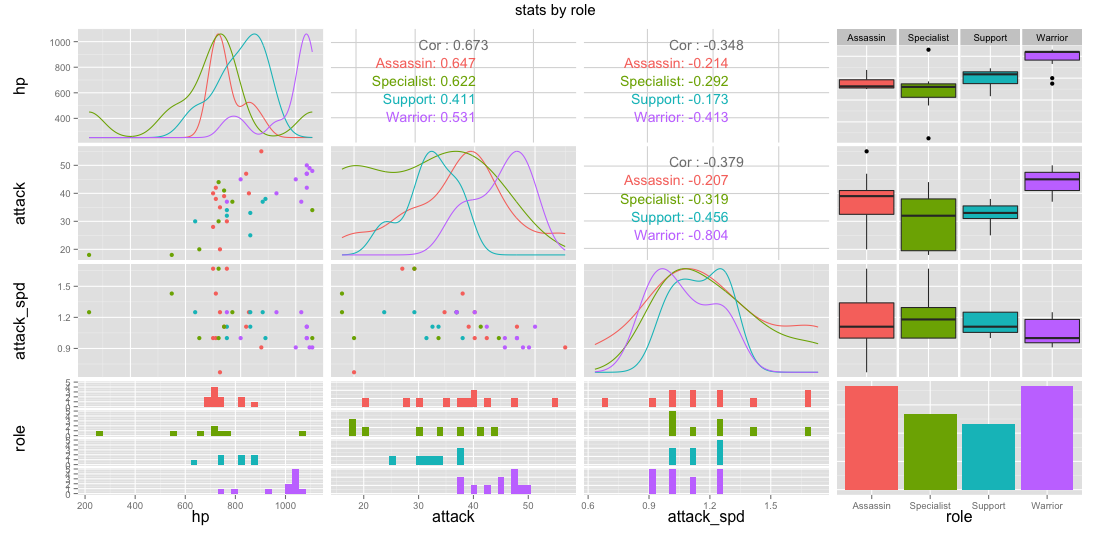
Specialist and support heroes don't deal as much damage as assassins or warriors. Melee characters also seem to pack more of a punch. All these numbers make sense from a game balance perspective.
Conclusion
So in about 20 lines of (very straightforward) code we have;
- retreived the html of a website
- parsed through the html to find nodes of interest
- parsed the nodes of interest
- visualised the result with two plots
In python, I would need to use beautiful soup as well as requests and matplotlib to get to a similar result, both of which feel like different styles of api. This is something R is becomming very good at, the entire language feels as the same api.
The html_nodes function feels lovely if you just want to quickly select a few things based of css-selectors. It plays very nicely with the %>% operator too. It even has support for rare css-selectors like :not. Very cool.
R and python: always contending.
Source
You can download the .Rmd file for this post here.
You should also be able to find this blog on: r-bloggers